知识图谱
1
2
3
4
5
6
7
8
9
@inproceedings{megdiche2016extensible,
title={An extensible linear approach for holistic ontology matching},
author={Megdiche, Imen and Teste, Olivier and Trojahn, Cassia},
booktitle={International Semantic Web Conference},
pages={393--410},
year={2016},
organization={Springer}
}
-2
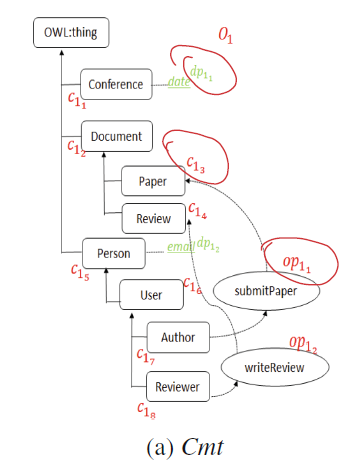
本体匹配
目前的方法:自动匹配和半自动匹配
成对匹配–>整体本体匹配(本文)
模式级的,基于maximum-weighted graph matching problem
概述:
In the pre-processing step, we apply element-level matchers and then aggregate the results in order to produce similarities between the entities of the ontologies. In the processing step, we instantiate the different elements of the linear program (decision variables and linear constraints) and then resolve the model by using the CPLEX solver.
**pre-processing step: **similarity matrices are computed between each pair of ontologies for classes, object properties and data properties
Linear Program:
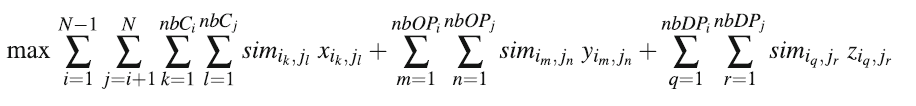
:speech_balloon:: 说一下自己的理解,这个模型OWL的三种属性进行比对,之后判断本体的相似度
1
2
3
4
5
6
7
8
9
@inproceedings{kimmig2017collective,
title={A collective, probabilistic approach to schema mapping},
author={Kimmig, Angelika and Memory, Alex and Getoor, Lise and others},
booktitle={2017 IEEE 33rd International Conference on Data Engineering (ICDE)},
pages={921--932},
year={2017},
organization={IEEE}
}
-1
早期的方法使用元数据(模式约束)和属性对应(也就是模式匹配)来创建与元数据一致的映射,以及等等方法,但这些方法只适用于一致性或完整性的输入。
借用probabilistic reasoning techniques,使用probabilistic soft logic (PSL),可用于知识图谱识别和数据融合
本文的的方法Collective Mapping Discovery(CMD),解决如下挑战:
- Dirty or Ambiguous Metadata
- Unexplained Data
- Data Errors
- Unknown Values
==//todo 公式太复杂了,看不懂,留待之后再看==
1
2
3
4
5
6
7
@inproceedings{zhu2017iterative,
title={Iterative entity alignment via knowledge embeddings},
author={Zhu, Hao and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI)},
year={2017}
}
-1
基于TransE的知识嵌入( TransE和PTransE)、联合嵌入(Translation-based Model 将关系嵌入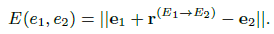 ,Linear Transformation Model 实体间的矩阵转换
,Linear Transformation Model 实体间的矩阵转换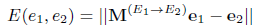 ,将一样的实体的模型参数共享)和==迭代对齐(硬对齐:直接将新实体求两实体中值,代入并迭代,软对齐:创建新集合,映射代入)==,最后衡量三部分目标函数和
,将一样的实体的模型参数共享)和==迭代对齐(硬对齐:直接将新实体求两实体中值,代入并迭代,软对齐:创建新集合,映射代入)==,最后衡量三部分目标函数和

1
REGAL: Representation Learning-based Graph Alignment
Step 1: Node Identity Extraction
structural identity
degrees & neighbors up to k hops
attribute-based identity
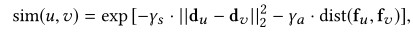
Step 2: Efficient Similarity-based Representation
implicit matrix factorization-based approach
Step 2a:Reduced n × p Similarity Computation
Step 2b: From Similarity to Representation
Step 3: Fast Node Representation Alignment
1
2
Bootstrapping Entity Alignment with Knowledge Graph Embedding
-2
BootEA code 代码很规范
一种自举方法来实现基于嵌入的实体对齐。它迭代地将可能的实体对齐标记为训练数据,用于面向学习对齐的KG嵌入。此外,该算法采用对齐编辑方法,以减少迭代过程中的误差积累。
通过正例和负例,用limit-based loss,进行嵌入
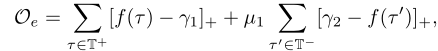
Bootstrapping对齐,每次迭代检查已对齐实体标记,选择能带了更多对齐可能性的实体
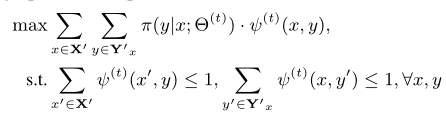
1
2
3
4
5
6
7
8
@inproceedings{shi2018open,
title={Open-world knowledge graph completion},
author={Shi, Baoxu and Weninger, Tim},
booktitle={Thirty-Second AAAI Conference on Artificial Intelligence},
year={2018}
}
-KGC
-1
从相关文本中,使用关系依赖内容掩蔽,掩盖不相关的文本,使用完全卷积网络(FCN)提取基于单词的嵌入,将提取的嵌入与KG中的现有实体进行比较,以解析目标实体的排序列表。
1
Non-translational Alignment for Multi-relational Networks
我们建议非转换方法,旨在利用概率模型对齐任务提供更健壮的解决方案,通过探索结构属性以及利用锚项目每个网络到相同的向量空间的过程中学习个体网络的表示
:speech_balloon:对于问题的描述很清晰,通过源实体、目标实体、关系的对齐,方法参考性目前不强
1
2
3
4
5
6
7
8
@inproceedings{zhu2019neighborhood,
title={Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs.},
author={Zhu, Qiannan and Zhou, Xiaofei and Wu, Jia and Tan, Jianlong and Guo, Li},
booktitle={IJCAI},
pages={1943--1949},
year={2019}
}
-1
通过门控机制获取多跳信息,注意力机制聚集邻居,用GCN学习邻居级别的表示,同时引入关系向量。
组件
vanilla GCN (Kipf and Welling 2017)
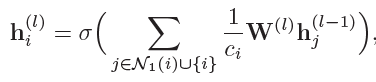
R-GCN (Schlichtkrull et al. 2018) 考虑邻居关系
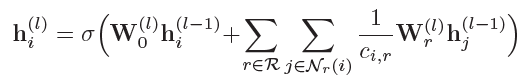
(公式不全,核心公式)
门控多跳邻居聚合
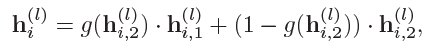
注意力机制
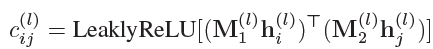
聚合
损失
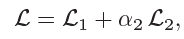
对齐损失
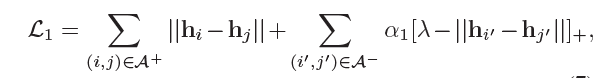
关系损失
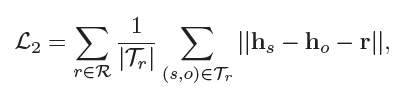
拓展
考虑多跳
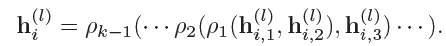
1
2
3
4
Learning to Exploit Long-term Relational Dependencies in Knowledge Graphs
-实体对齐
-RNN
-2
整体结构图
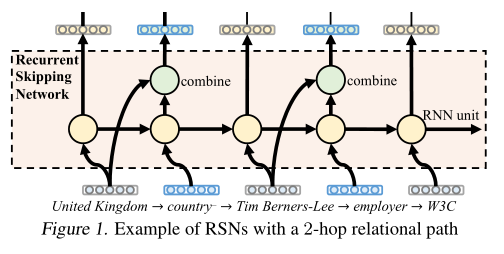
Recurrent skipping network
Skipping Mechanism
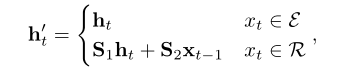
相比rnn,每次到下一层时,如果这层是对关系的处理,就将上一层节点也加入
Biased Random Walks
combine the depth and cross-KG biases 优先深度,优先跨图。
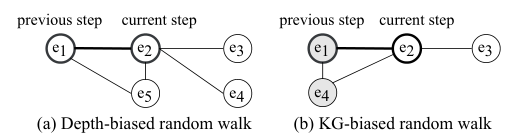
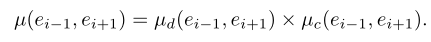
对于跨图的路径,论文中说对于输入的两个图,首先构建joint KG,路径是通过seed alignment进行连接,其多少影响模型效果。

noise contrastive estimation
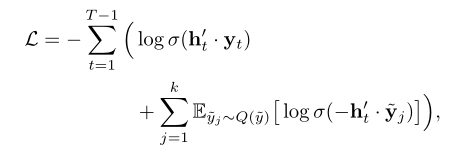
1
2
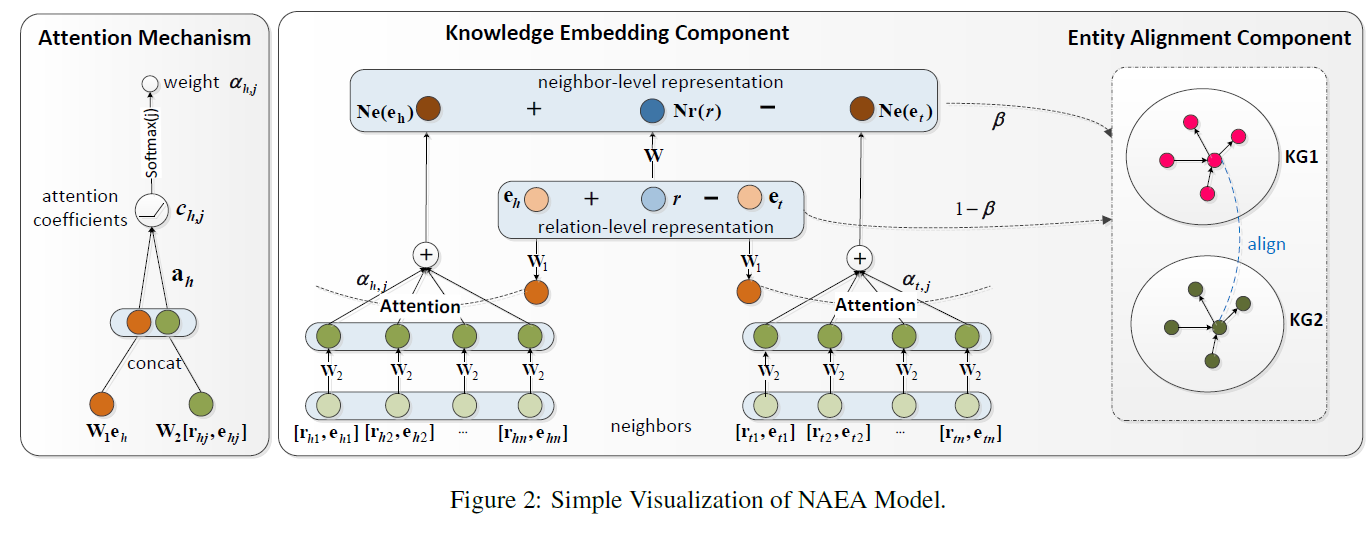
Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs
-2
在知识图中基于注意力合并邻居级和关系级特征信息,以执行多语言实体对齐任务。
1
2
3
4
5
6
7
8
@article{das2020probabilistic,
title={Probabilistic Case-based Reasoning for Open-World Knowledge Graph Completion},
author={Das, Rajarshi and Godbole, Ameya and Monath, Nicholas and Zaheer, Manzil and McCallum, Andrew},
journal={arXiv preprint arXiv:2010.03548},
year={2020}
}
-1
基于KNN收集知识库中相似实体的推理路径来预测实体的属性,给出可能项的概率。将相似实体先聚类,在桶内查找使用简单的路径统计计算频率和精度。
1
2
Realistic Re-evaluation of Knowledge Graph Completion Methods: An Experimental Study
-1
移除不现实的三元组,从而提升知识图谱补全方法的准确度,重新评估方法
1
2
3
4
5
6
7
8
9
10
@inproceedings{yue2020representation,
title={Representation-based completion of knowledge graph with open-world data},
author={Yue, Kun and Wang, Jiahui and Li, Xinbai and Hu, Kuang},
booktitle={2020 5th International Conference on Computer and Communication Systems (ICCCS)},
pages={1--8},
year={2020},
organization={IEEE}
}
-KGC
-1
将元组关系映射到向量空间,比较相似性
1
2
3
A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs
-survey
-2
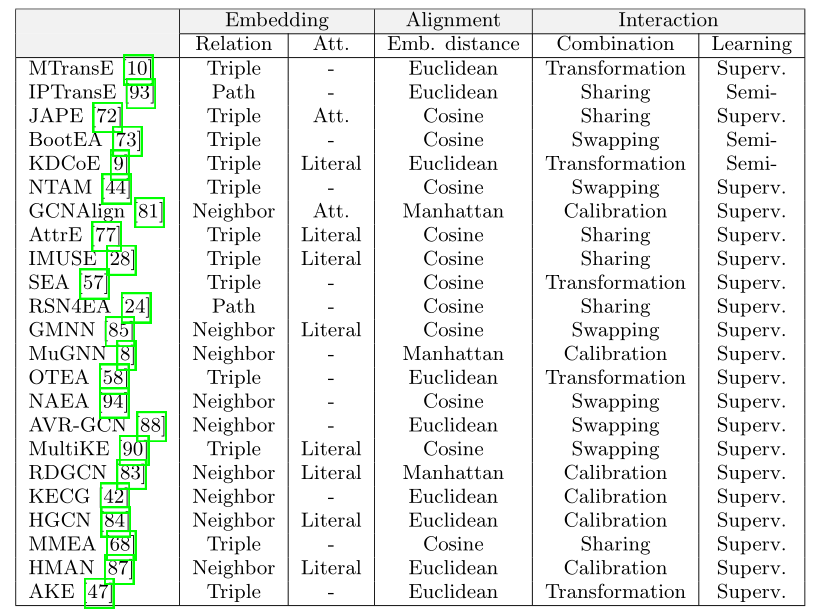
Knowledge Graph Embedding 方法分类:
translational models,e.g., TransE [5], TransH [82], TransR [49] and TransD [33];
semantic matching models, e.g., DistMult [86], ComplEx [76],HolE [54], SimplE [36], RotatE [71] and TuckER [3];
deep models, e.g., ProjE [66], ConvE [13], R-GCN [63], KB-GAN [7] and DSKG [25].
Conventional Entity Alignment 实体对齐方法:
One is based on equivalence reasoning mandated by OWL semantics [22, 34].
The other is based on similarity computation, which compares symbolic features of entities [39, 65, 70].
Recent studies also use statistical machine learning [15, 31, 32] and crowdsourcing [96] to improve the accuracy.
Embedding-based Entity Alignment
Many existing approaches [10, 47, 57, 58, 72,73, 77, 93] employ the translational models (e.g., TransE [5]) to learn entity embeddings for alignment based on relation triples.
Some recent approaches [8, 42, 81, 83, 85, 84, 88, 94] employ graph convolutional networks (GCNs) [38, 78].
some approaches incorporate attribute and value embeddings [9, 28, 72, 77, 83, 84, 87, 90].
there are some approaches for (heterogeneous information) network alignment [29, 44, 89] or cross-lingual knowledge projection [56], which may also be modified for entity alignment.
Embedding Module
The embedding module seeks to encode a KG into a low-dimensional embedding space.
relation embedding leverages relational learning techniques to capture KG structures
Triple-based embedding captures the local semantics of relation triples
![image-20211214152726041]()
· denotes the L1- or L2-norm of vectors. Loss
marginal ranking loss
logistic loss
limit-based loss
generate negative triples
uniform negative sampling
truncated sampling
Path-based embedding exploits the long-term dependency of relations spanning over relation paths
![image-20211214154257216]()
comb(·) is a sequence composition operation such as sum.
Neighborhood-based embedding uses the subgraph structure constituted by a large amount of relations between entities
![image-20211214160145812]()
with ˆA=A+I and I is an identity matrix.ˆD is the diagonal degree matrix of ˆA. W is the learnable weight matrix. σ(·) is the activation function such as tanh(·).
attribute embedding exploits attribute triples of entities.
- Attribute correlation embedding considers the correlations among attributes.
- Literal embedding introduces literal values to attribute embedding.
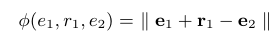
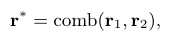
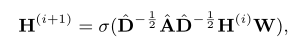
Alignment Module
uses seed alignment as labeled training data to capture the correspondence of entity embeddings.
distance metric
Cosine, Euclidean and Manhattan distance
alignment inference strategy
Greedy search
collective search
Kuhn-Munkres algorithm, heuristic algorithm and stable marriage algorithm
Interaction Mode
Combination modes
- Embedding space transformation embeds two KGs in different embedding spaces and learns a transformation matrix M between the two spaces using seed alignment
Embedding space calibration encodes two KGs into a unified embedding space. minimizes e1−e2 for each (e1, e2) to calibrate the embeddings of seed alignment - parameter sharing directly configures e1=e2
- parameter swapping swaps seed entities in their triples to generate extra triples as supervision
Learning strategies
Supervised learning leverages the seed alignment as labeled training data.
- For embedding space transformation, seed alignment is used to learn the transformation matrix.
- For space calibration, it is used to let aligned entities have similar embeddings.
Semi-supervised learning uses unlabeled data in training, e.g.,
- self-training [73, 93] iteratively proposes new alignment to augment seed alignment.
- co-training [9] combines two models learned from disjoint entity features and alternately enhances the alignment learning of each other.
Unsupervised learningneeds no training data.
We have not observed any embedding-based entity alignment approaches using unsupervised learning.
1
2
Multi-Modal Knowledge Graph Construction and Application: A Survey
-2
目录
多模态KG的定义、发展、意义、挑战,
从图像到符号构建KG/从符号到图像构建KG
MMKG内应用:实体对齐、连接预测等
2 定义和准备工作
两种MMKG

准备
多模态任务
- 图像字幕
- 视觉基础
- 可视化问答
- 跨模态检索
多模态学习
- 多模态表示:现有的研究要么将多模态投影到一个统一的空间[38]和VGG[39]、ResNet[40],要么将每个单个模态表示在自己的向量表达空间中,该空间满足某些约束条件,如线性相关性[41]。
- 多模态翻译。多模态翻译学习从一个模态中的源实例到另一个模态中的目标实例的翻译。基于实例的翻译模型通过字典[37],[42]在不同的情态之间架起桥梁,而生成性翻译模型则建立了一个更灵活的模型,可以将一种情态转换为另一种情态[43],[44]。
- 多模态对齐。多模态对齐旨在发现不同模态之间的对应关系。它既可以直接应用于视觉基础等多模态任务,也可以作为多模态预训练语言模型中的预训练任务
- 多模态融合。多模态融合指的是将来自不同模态的信息连接起来进行预测的过程[27],其中应用了各种注意机制,如门控跨模态注意[46]、自底向上注意[47]等,以模拟跨模态模块中不同类型特征之间的交互。5)
- 多模式合作学习。多模式合作学习旨在通过调整其他模式的资源来缓解某一模式中资源不足的问题[27]。
多模态预训练语言模型。基于一个包含文本图像对的大规模无监督多模态数据集,
3 构建
MMKG结构的本质是将传统KG中的符号知识(包括实体、概念和关系等)与其对应的图像相关联。完成这项任务有两种相反的方法:(1)用KG标记图像;
CV社区开发了许多图像标记解决方案,可以利用这些解决方案在图像上标记知识符号(KG)。大多数图像标签解决方案学习从图像内容到各种标签集的映射,包括对象、场景、实体、属性、关系、事件和其他符号。学习过程由人工标注的数据集进行监督,该数据集要求群组工作人员绘制边界框,并用给定的标签标注图像或图像区域,如图2所示。一些著名的基于图像的视觉知识提取系统如表2a所示,可用于通过图像标记构建MMKG。根据要链接的符号类别,将图像链接到符号的过程可分为几个细分任务:视觉实体/概念提取(第3.1.1节)、视觉关系提取(第3.1.2节)和视觉事件提取(第3.1.3节)。
(2)用KG标记图像。
符号基础是指找到适当的多模态数据项(如图像)以表示传统知识中存在的符号知识的过程。与图像标注方式相比,符号联系方式在MMKG施工中的应用更为广泛。大多数现有MMKG都是以这种方式建造的,如表2b所示。
在本小节的其余部分中,我们将介绍在几个细分任务中将符号与图像联系起来的过程:实体联系(第3.2.1节)、概念联系(第3.2.2节)和关系联系(第3.2.3节)。
1.基于实体的
实体接地旨在将KG中的实体接地到相应的多模态数据,如图像、视频和音频[12]。现有的工作主要侧重于将实体与相应的图像联系起来。
挑战。将实体接地到图像的主要挑战如下:1)如何以低成本为实体找到足够多的高质量图像?2) 如何从大量噪声中选择与实体最匹配的图像?
进步。有两个主要来源可以找到实体的图像:(1)来自在线百科全书(如维基百科)和(2)通过网络搜索引擎从互联网。
2.基于概念的
概念基础旨在为视觉概念找到具有代表性的、有区别的和多样的图像。
挑战尽管一些视觉上统一的概念(如男人、女人、卡车和狗)也可3.以通过3.2.1中介绍的实体基础方法基础到图像,其他概念的符号基础面临着新的挑战:1)并不是所有的概念都能正确地可视化。例如,非宗教主义者不能基于某个特定的形象。如何区分可视概念和非可视概念?2) 如何从一组相关图像中找到一个可视化概念的代表性图像?请注意,可视化概念的图像可能非常多样。例如,说到公主,人们经常会想到几个不同的形象,比如迪士尼公主、历史电影中的古代公主或新闻中的现代公主。因此,我们必须考虑图像的多样性。
进步。为了应对上述挑战,相关研究分为三个任务:可视化概念判断、代表性图像选择和图像多样化。
3.基于关系的
关系基础是从图像数据语料库或互联网上找到可以代表特定关系的图像。输入可以是该关系的一个或多个三元组,输出应该是该关系最具代表性的图像。
挑战。当我们使用三元组作为查询来检索关系的图像时,排名靠前的图像通常与三元组的主语和宾语更相关,但与关系本身无关。如何找到能够反映输入三元组语义关系的图像?
进步。现有的关系基础研究主要集中在空间或动作关系上,如左的、上的、骑的和吃的。
4 应用
1.MMKG内的应用
n-MMKG应用指的是在MMKG范围内执行的任务,其中已经学习了实体、概念和关系的嵌入。因此,在介绍MMKG应用程序之前,我们先简要介绍一下MMKG中知识的分布式表示学习,也称为MMKG嵌入。
- 连接预测
- 元组分类
- 实体分类
- 实体对齐
2.MMKG外的应用
- 多模态实体识别与连接
- 视觉问答
- 图文匹配
- 多模态生成任务
- 多模式推荐系统
6 结论
我们是第一个全面调查由文本和图像构建的MMKG的现有工作的人。我们系统地回顾了MMKG施工和应用方面的现有工作。我们比较了主流MMKG的内容和构造方式。我们分析了MMKG结构和应用中不同解决方案的优缺点。我们不仅指出了MMKG建设和应用中现有任务的一些潜在机会,还列出了MMKG建设和应用的一些有希望的未来方向
1
2
3
Generating Explanations to Understand and Repair Embedding-based Entity Alignment
-Wei Hu
-Nanjing University
通过局部子图,解释实体对齐的结果
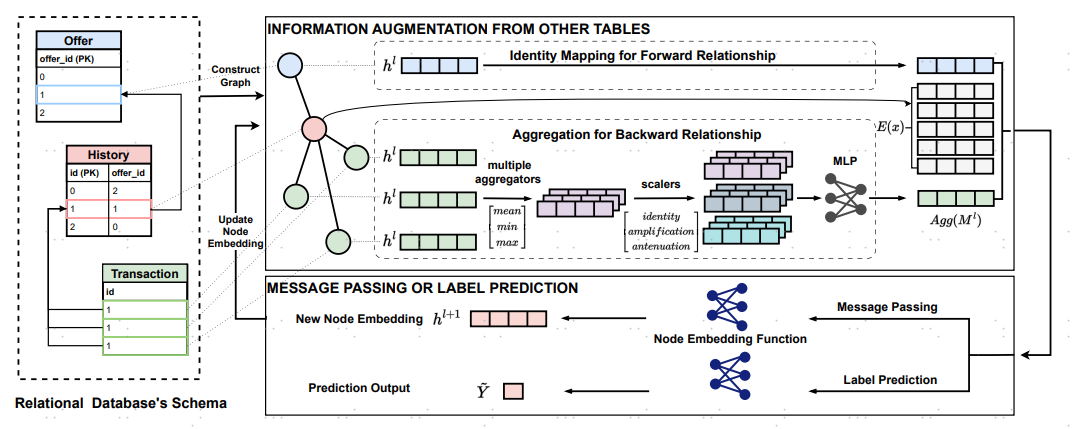
GFS: Graph-based Feature Synthesis for Prediction over Relational Databases
将表列生成向量,查找关系表,预测标签