跟李沐大佬读论文
方法论
pass 1:标题、摘要、结论、图表、实验
pass 2:通读、总体流程、文献
pass 3:详细、实现
Transformer
Attention is all you need
位置嵌入:引入位置信息,直接与词嵌入相加
注意力机制:给和自身相似的分配更高的权重。QKV是同样的向量复制三份
多头:学习到多种在不同空间的特征
残差:避免梯度消失 https://www.bilibili.com/video/BV1Di4y1c7Zm?p=4&spm_id_from=pageDriver
Mask:避免对后面的词进行计算
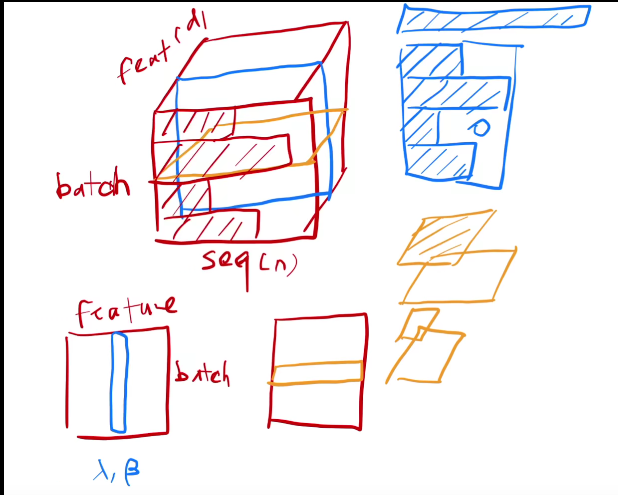
Batch Normal和Layer Normal的区别?
BN优点:解决内部协变量偏移(有疑?),缓解梯度饱和
缺点:batch_size小时效果差,在RNN中效果差
LN:对同一个样本的所有单词进行缩放