论文阅读笔记
我姑且把论文的阅读方式分为四种:精读3、通读2、略读1、不读,目前结合自己的情况,通读略读的论文放在这里,为了留下一个印象,同时为以后的工作提供参考。精读的论文批注本来是储存在文档上了,但后来发现当自己需要回顾的时候,不能一个一个打开文档,而且自己鸡的记忆,所以还是放在这里供后期回顾总结。
本目录以方向分类,以发表时间为序。
目录
知识图谱 (见2021-12-13-知识图谱论文阅读笔记)
内容
图
1
Learning Graph Representations with Embedding Propagation
https://zhuanlan.zhihu.com/p/36027021
Forward messages Backward messages
与Message Passing Neural Network (MPNN) 的不同:
- unsupervised
- combines label embeddings into a joint node
- reconstructing each node’s representation from neighboring nodes’ representations
首先将节点v 的邻居节点的属性向量表达结合起来,重建出节点v 的属性向量表达;接着,将节点 v 本身的属性向量与重建出来的属性向量的差值的梯度,反向传播给它的邻居,来更新邻居的属性向量,不断迭代,直至收敛(或迭代一定次数)。
1
2
3
4
5
6
7
@article{coupette2021graph,
title={Graph Similarity Description: How Are These Graphs Similar?},
author={Coupette, Corinna and Vreeken, Jilles},
journal={arXiv preprint arXiv:2105.14364},
year={2021}
}
-2
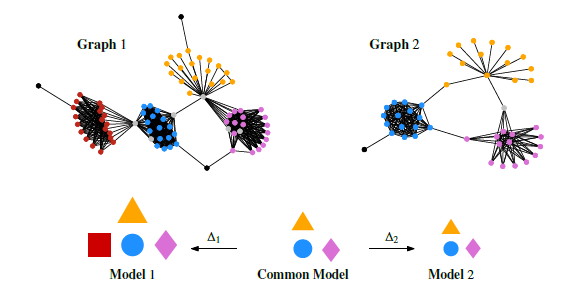
主要内容:
MOMO采用联合压缩图,比较图的相似性程度
BEPPO为单个输入图发现可解释的摘要,GIGI使用它们来揭示它们共享的和特定的结构,从中计算信息相似度得分
理论:
非正式相似度描述
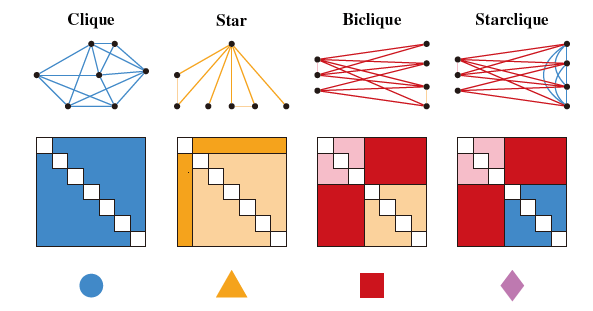
论文将图简化为四种基本结构(cliques、Stars、Bicliques、Starcliques),通过邻接矩阵,将节点集大小作为节点得分,连通性约束为边密度。
![image-20210914202743349]()
编码
- Graph Under an Individual Model
- Individual Model
- Common Model
- Transformations
度量
Normalized Model Distance
\[\operatorname{NMD}\left(G_{1}, G_{2}\right)=\frac{L\left(M_{12}\right)+L\left(\Delta_{1}, \Delta_{2}\right)-\min \left\{L\left(M_{1}\right), L\left(M_{2}\right)\right\}}{\max \left\{L\left(M_{1}\right), L\left(M_{2}\right)\right\}}\]正式
![主理论]()

算法:
图摘要:BEPPO,算法1
全图查找高度节点,构建基本结构
模型配准:GIGI,算法2
查找公共结构和独特的结构
相关工作
图相似性度量,图摘要
Tips:
data, code, and results均可获得
数据
1
2
Deep Learning for Blocking in Entity Matching: A Design Space Exploration
-2
表匹配
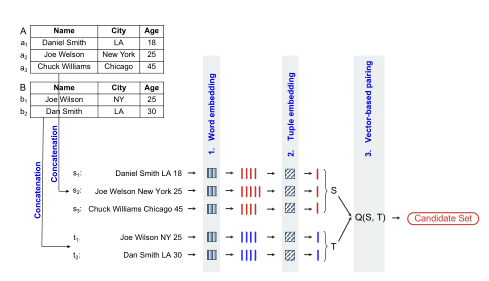
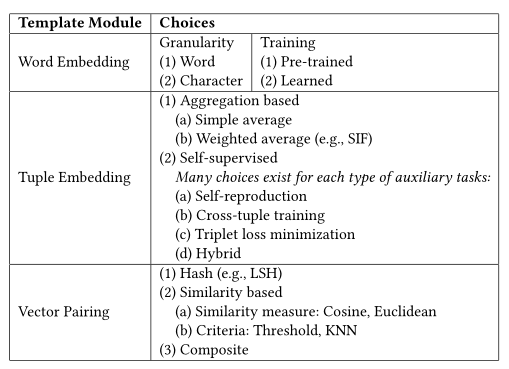
1
2
High-Dimensional Similarity Query Processing for Data Science
-2
(1) data models and the way of which we convert raw data (text, images, video, etc.) to high-dimensional data;
(2) similarity/distance functions, mainly Hamming distance for binary vectors and Euclidean distance and cosine similarity (angular distance) for real-valued vectors;
(3) query types, i.e., search and join queries, or thresholded and top-𝑘 (𝑘-NN) queries, depending on the dimension of categorization;
Locality Sensitive Hashing
Learning to Hash.
Partition-based Methods
Neighborhood-based Methods.
𝑘-NN graph [5],
- hierarchical navigable small world [14],
- navigating spreading-out graph [6].
https://www.sklearncn.cn/7/#161
1
2
AdaTyper: Adaptive Semantic Column Type Detection
2023
输入列,获取列类型
header, -using semantic matching.
column values, -set of regular expression
and embeddings of columns- basic tree-based machine learning model
1
2
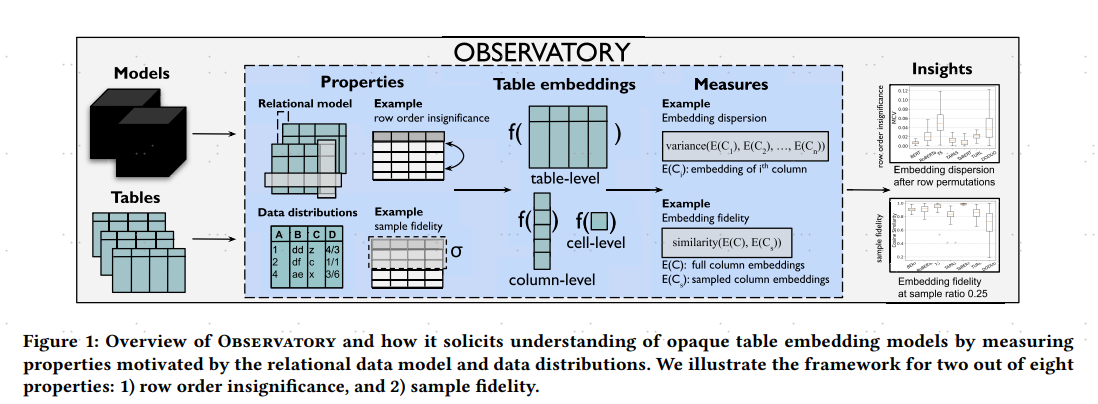
Observatory: Characterizing Embeddings of Relational Tables
2024
- 关系属性
- Row Order Insignificance行顺序、
- Column Order Insignificance列顺序
- Join Relationship表join
- Functional Dependencies函数依赖
- 数据分布属性
- Sample Fidelity
- Entity Stability
- Perturbation Robustness
- Heterogeneous Context
1
2
3
LEDD: Large Language Model-Empowered Data Discovery in Data Lakes
-清华大学
2025
we propose LEDD, an end-to-end system with an extensible architecture that leverages LLMs to provide hierarchical global catalogs with semantic meanings and semantic table search for data lakes
:speech_balloon:: 这论文能发sigmod?贡献、配图都懒得看,有用再看吧
1
2
3
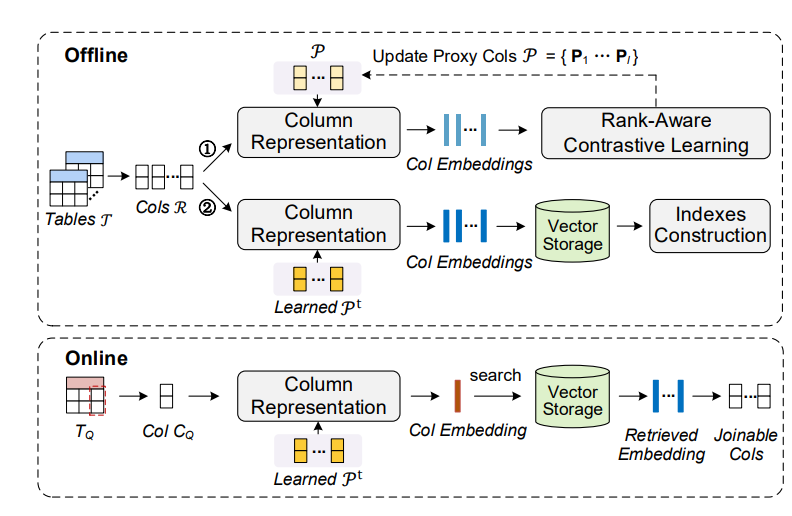
Snoopy: Effective and Efficient Semantic Join Discovery via Proxy Columns
- TKDE
- Yunjun Gao, zhejiang u
Snoopy, an effective and efficient semantic join discovery framework powered by proxy columns. We devise an approximate-graph-matching-based column projection function to capture column-to-proxy-column relationships, ensuring size-unlimited and permutation-invariant column representations. To acquire good proxy columns, we present a rank-aware contrastive learning paradigm to learn proxy column matrices for embedding pre-computing and online query encoding
1
2
3
4
Humans, Machine Learning, and Language Models in Union: A Cognitive Study on Table Unionability
- 2025
- sigmod-HILDA
- 人机交互、表联合
本研究调查了在数据发现中确定表的可联合性的人类行为。我们设计了一项实验性调查并进行了全面分析,在此过程中评估了人类在表可联合性方面的决策。我们利用分析中的观察结果开发了一个机器学习框架,以提升人类的(原始)表现。此外,我们还进行了初步研究,比较了大型语言模型(LLM)与人类的表现,结果表明通常更好地考虑两者的结合。我们相信,这项工作为未来开发高效数据发现的人机协作系统奠定了基础。
1
2
3
TableCopilot: A Table Assistant Empowered by Natural Language Conditional Table Discovery
- ICDE 25
- Zhejiang University
贡献度不够,套壳gpt,做了一个二分类,执行分析or表发现
1
2
3
4
5
6
@article{hong2025next,
title={Next-generation database interfaces: A survey of llm-based text-to-sql},
author={Hong, Zijin and Yuan, Zheng and Zhang, Qinggang and Chen, Hao and Dong, Junnan and Huang, Feiran and Huang, Xiao},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2025}
}
text to sql survey
图神经网络
1
2
3
4
5
6
7
8
9
10
11
12
@article{wu2020comprehensive,
title={A comprehensive survey on graph neural networks},
author={Wu, Zonghan and Pan, Shirui and Chen, Fengwen and Long, Guodong and Zhang, Chengqi and Philip, S Yu},
journal={IEEE transactions on neural networks and learning systems},
volume={32},
number={1},
pages={4--24},
year={2020},
publisher={IEEE}
}
-survey
-2
Graph neural networks vs. network embedding
network embedding:用低维向量表示网络节点,既保留网络拓扑结构又保留节点内容信息
GNN :旨在以端到端方式处理图相关任务的深度学习模型
GNN可以通过一个图形自动编码器框架来解决网络嵌入问题。另一方面,网络嵌入还包含其他非深度学习方法,如矩阵分解和随机游动等
传统深度学习方法不适用于图的原因:
- 图是不规则的
- 图数据之间有关联
图神经网络:
图卷积网络(Graph Convolution Networks,GCN)
- 基于谱(spectral-based):缺点:需要将整个图加载到内存中以执行图卷积
- 基于空间(spatial-based)
图注意力网络(Graph Attention Networks)
Graph Attention Network (GAT) 优点:自适应地学习邻居的重要性权重
Gated Attention Network (GAAN) 优点:自适应地学习邻居的重要性权重
Graph Attention Model (GAM)
图自编码器( Graph Autoencoders)
图生成网络( Graph Generative Networks)
基于GCN
- Molecular Generative Adversarial Networks (MolGAN)
- Deep Generative Models of Graphs (DGMG)
other
GraphRNN
NetGAN
图时空网络(Graph Spatial-temporal Networks)
1
Heterogeneous Graph Attention Network
然而,对于包含不同类型节点和链接的异构图,它在图神经网络中并没有得到充分的考虑。异构性和丰富的语义信息给异构图神经网络的设计带来了巨大的挑战。
现实世界中的图形通常具有多种类型的节点和边,也称为异构信息网络(HIN)
现实世界的数据往往兼具“结构”与“语义”双重属性。传统的图神经网络(GNN)擅长处理拓扑结构,但在理解节点背后的丰富文本语义时往往力不从心;而大语言模型(LLM)虽然拥有强大的语义推理与泛化能力,却天生对非欧几里得的图结构水土不服。如何打通这两个模态?目前的学术界主要分化出了两条截然不同的路线:
LLM-as-Enhancer:用 LLM 给 GNN 打辅助。Generalization Principles for Inference over Text-Attributed Graphs with Large Language Models (ICML 2025)
LLM-as-Predictor:让 LLM 亲自上场做推理。GOFA: A Generative One-For-All Model for Joint Graph Language Modeling (ICLR 2025)
这两条路,哪条才是通往下一代 Graph AI 的坦途?
回顾这些图学习与大模型结合的多种探索,LLM-BP 代表了Enhancer 范式的简洁追求,证明了只要特征足够好,经典的启发依然能打败复杂的微调。GOFA 则代表了Predictor 范式的宏大理想,它用“三明治架构”将 GNN 与 LLM 深度融合,实现了“One-For-All”的零样本推理。而 CROSS 则提醒我们时间维度的重要性,在动态图中,只有捕捉到“语义漂移”,才能避免刻舟求剑。
将这三者放在一起审视,我们能清晰地看到横亘在整个领域面前的性能-效率悖论。Training-free的策略凭借只推理一次 Embedding,实现了工业级的可用性,但牺牲了对复杂模式的把握;而处于顶层的 Generative Predictor 虽然描绘了GFM的宏大愿景,推理成本却指数级爆炸。这迫使我们反思:在追求benchmark上的最高分时,我们是否牺牲了太多的现实可行性?
另一点是泛化性的悖论。我们往往认为训练得越多,效果越好,但在图与 LLM 的结合中,事实却常常相反。微调虽然能让模型在源域上表现优异,却容易让 LLM 过拟合于特定的结构模式,导致在跨域迁移时出现负迁移。相反,像 LLM-BP 这样完全不训练 GNN、仅依靠 LLM 通用推理能力的策略,反而保留了最强的跨域适应性。我们距离一个兼顾泛化性和强大能力的图基础模型,可能还有很长的路要走。
最后,回到Enhancer与Predictor的较量。Enhancer 只是把 LLM 当作昂贵的特征提取器,而 Predictor 试图让 LLM 强行处理每一条请求,这两种极端都有各自的突出问题。利用语义的最优模式,尚待后续研究继续探索。
信息系统
1
2
3
4
5
6
7
8
@inproceedings{lian2018high,
title={High-order proximity preserving information network hashing},
author={Lian, Defu and Zheng, Kai and Zheng, Vincent W and Ge, Yong and Cao, Longbing and Tsang, Ivor W and Xie, Xing},
booktitle={Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery \& Data Mining},
pages={1744--1753},
year={2018}
}
-1
信息网络嵌入:基于MF的信息网络哈希(INH-MF)算法来学习能够保持高阶近似的二进制代码。我们还建议汉明子空间学习,每次只更新部分二进制代码,以扩大INH-MF
分布式
1
2
3
4
5
6
7
8
9
10
11
@article{stolte2002polaris,
title={Polaris: A system for query, analysis, and visualization of multidimensional relational databases},
author={Stolte, Chris and Tang, Diane and Hanrahan, Pat},
journal={IEEE Transactions on Visualization and Computer Graphics},
volume={8},
number={1},
pages={52--65},
year={2002},
publisher={IEEE}
}
-1
https://zhuanlan.zhihu.com/p/409131883
https://zhuanlan.zhihu.com/p/388391672
湖仓一体化下,分布式查询处理引擎Polaris,包括查询优化和执行调度等方案。
==// todo==
