1
MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and Modalities
现有的知识转移方法主要有两种:知识蒸馏和迁移学习。 知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。
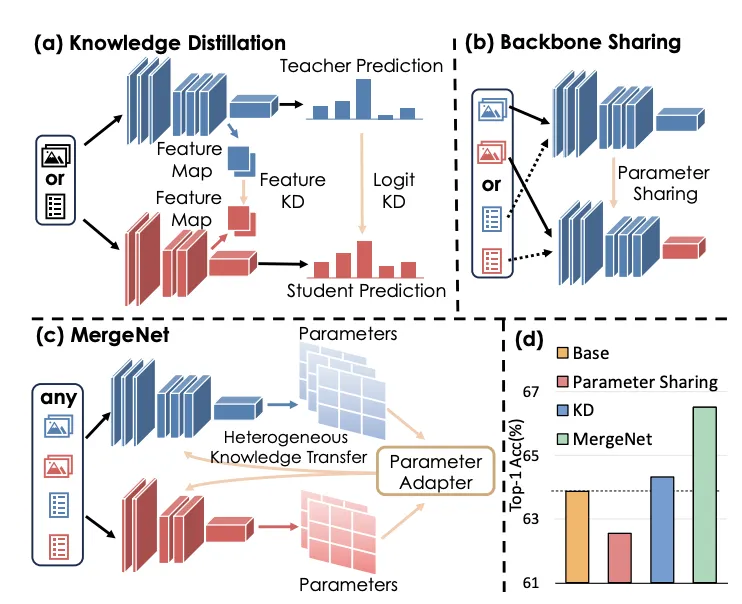
知识蒸馏、骨干共享和 MergeNet 的比较
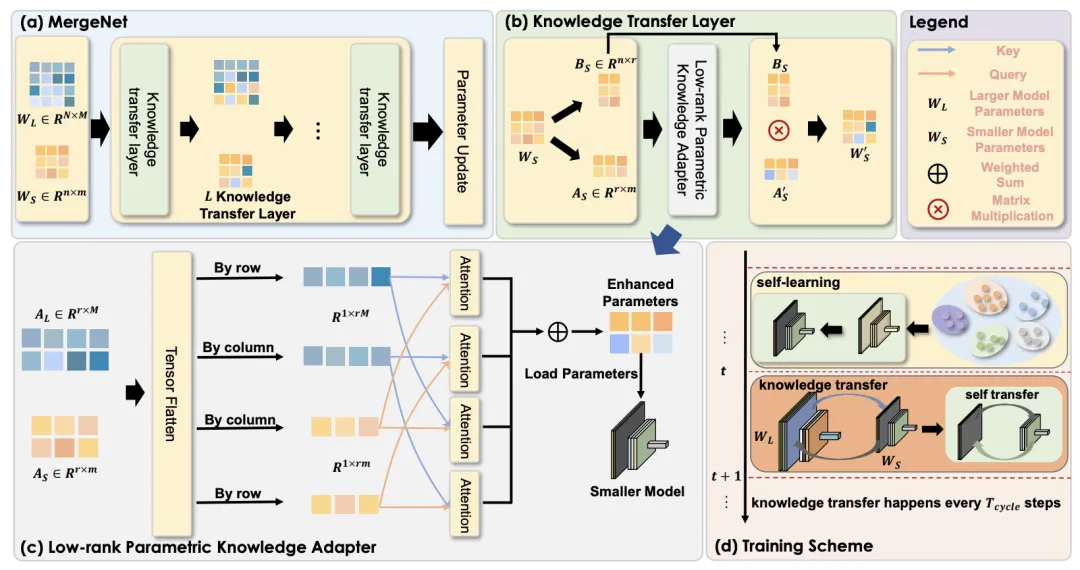
MergeNet 框架
1
2
3
MUST: An Effective and Scalable Framework for Multimodal Search of Target Modality
-Yunjun Gao
-Zhejiang University
将图实体转换为向量,构建图索引,搜索
These baselines either merge the results of separate vector searches for each modality or perform a single-channel vector search by fusing all modalities.
Our framework employs a hybrid fusion mechanism, combining different modalities at multiple stages. Notably, we leverage vector weight learning to determine the importance of each modality, thereby enhancing the accuracy of joint similarity measurement. Additionally, the proposed framework utilizes a fused proximity graph index, enabling efficient joint search for multimodal queries. MUST offers several other advantageous properties, including pluggable design to integrate any advanced embedding techniques, user flexibility to customize weight preferences, and modularized index construction.
我们的框架采用了混合融合机制,在多个阶段结合了不同的模式。值得注意的是,我们利用向量权重学习来确定每个模态的重要性,从而提高了联合相似性度量的准确性。此外,提出的框架利用融合接近图索引,使联合搜索多模态查询成为可能。MUST提供了其他几个有利的特性,包括可插入的设计,以集成任何先进的嵌入技术,用户定制权重偏好的灵活性,以及模块化的索引构造。
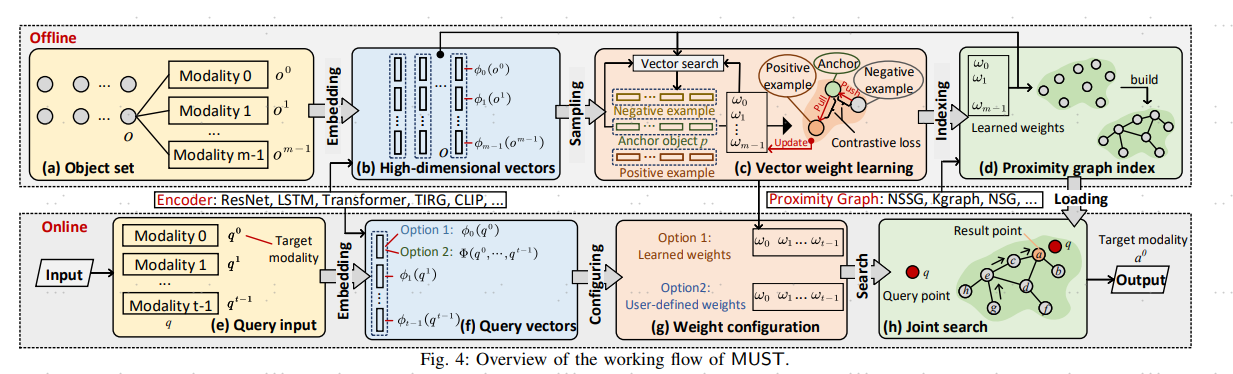
1
2
Connecting Multi-modal Contrastive Representations
浙江大学
论文地址:https://arxiv.org/abs/2305.14381
项目主页:https://c-mcr.github.io/C-MCR/
模型和代码地址:https://github.com/MCR-PEFT/C-MCR
wechat:「无需配对数据」就能学习!浙大等提出连接多模态对比表征C-MCR|NeurIPS 2023
这些缺乏配对数据的模态组合,往往和同一个中间模态具有大量高质量配对数据。 考虑到具有大量配对数据的模态间往往已经拥有预训练的对比表示,本文直接尝试通过枢纽模态来将不同模态间的对比表征连接起来,从而为缺乏配对数据的模态组合构建新的对比表征空间。
1
On the Essence and Prospect: An Investigation of Alignment Approaches for Big Models
https://arxiv.org/abs/2403.04204
wechat:大模型的对齐技术综述以及前沿讨论:个性化对齐和多模态对齐
大模型在人工智能领域取得了革命性的突破,但它们也可能带来潜在的担忧。为了解决这些担忧,引入了对齐技术,以使这些模型遵循人类的偏好和价值观。尽管过去一年取得了相当大的进展,但在建立最佳对齐策略时仍然存在各种挑战,例如数据成本和可扩展的监督,如何对齐仍然是一个悬而未决的问题。在这篇综述文章中,作者全面调查了价值对齐方法。文章首先解析对齐的历史背景,追溯到20世纪20年代(它来自哪里),然后深入探讨对齐的数学本质(它是什么),揭示了固有的挑战。在此基础上,作者详细检查了现有的对齐方法,这些方法分为三类:强化学习、监督式微调和上下文内学习,并展示了它们之间的内在联系、优势和局限性,帮助读者更好地理解这一研究领域。此外,还讨论了两个新兴主题:个性化对齐和多模态对齐,作为该领域的新前沿。展望未来,文章讨论了潜在的对齐范式以及它们如何处理剩余的挑战,展望了未来对齐的发展方向。
LLMs的对齐方法主要分为三种范式:基于强化学习的对齐、基于监督式微调的对齐和上下文内对齐。
1
2
3
4
5
6
7
@article{MRAGSurvey,
title={A Survey on Multimodal Retrieval-Augmented Generation},
author={Lang Mei, Siyu Mo, Zhihan Yang, Chong Chen},
year={2025},
organization={GitHub},
url={https://github.com/PanguIR/MRAGSurvey},
}
1
2
3
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey
- 2025
- 哈工大
- PLM 让文本嵌入从“专用”走向“通用”,现在正迈向“多模态+多语言+多任务”大一统。
- 数据合成 + 对比学习 + 大模型上下文窗口,是当前性能提升的三板斧。
- 下一步,嵌入模型需要“会推理、懂安全、能解耦”,而不仅是向量维度更高。
1
2
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
- 2025
We introduce MMEB-V2, a comprehensive benchmark that extends MMEB with five new task types spanning video and visual document domain. Next, we train VLM2Vec-V2, a general-purpose embedding model that supports text, image, video, and visual document inputs.